

众所周知,scrapy是一个经典的爬虫框架。但是我不建议大家使用这个框架,首先是这玩意已经是老古董级别,现在很少有围绕它的插件了。而且它还很重,写普通爬虫基本上也不需要使用这个。最重要的是有些公司老是问这个,一点意义都没有的东西老是问。
众所周知的还有scrapy可以使用scrapyd进行部署,通过api可以获取、控制爬虫的状态。于是有这么一个web可视化的框架scrapydWeb,专门用来可视化处理scrapyd,目前是年更一次的水平。
这个框架的出发点是好的,但是功能是不好用的。不得不品的就是他的删除进程功能,可以说是没有的。有些时候爬虫会出现长时间的N/A,或者获取不到item,这个时候你想删除这些进程,但是你会发现它不支持批量删除,它的进程状态都在数据库里面存着,去操作也很麻烦,只好一个一个删。
问题是它删一次就刷新一次页面,定时任务又会因为消耗的太慢堆积的非常多导致非常卡,更重要的是Forcestop根本杀不掉进程。。
于是就有了下面这段简单代码来帮忙:
a = """
library wk:xxx task_45_2025-02-14T06_00_00 2561977 03-31 22:04:10 2 days, 12:01:47 N/A N/A Stats Log Stop Forcestop
library wk:xxx task_46_2025-02-14T06_20_00 2621044 04-01 00:43:25 2 days, 9:22:32 N/A N/A Stats Log Stop Forcestop
library wk:xxx task_47_2025-02-14T06_40_00 2652661 04-01 02:09:00 2 days, 7:56:57 3210 0 Stats Log Stop Forcestop
"""
b = a.split('\n')
d = [c.split('\t')[3] for c in b if c and ("N/A" in c or "\t0\t" in c)]
[print(f'kill -9 {e}') for e in d]
我们要做的就是手动复制文本
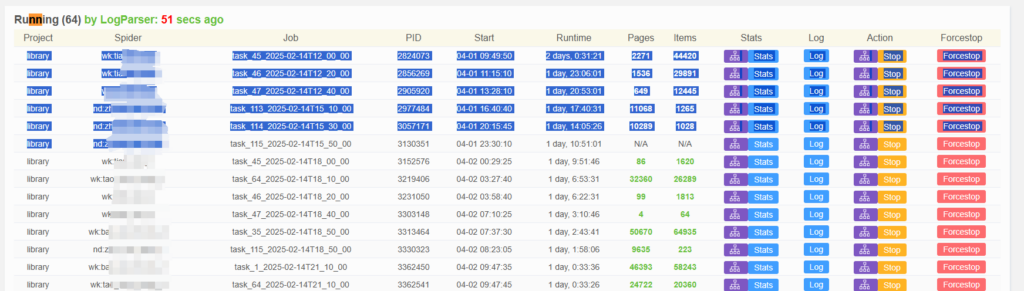
放到a变量里面运行一下,就可以得到items为N/A或者为0的情况的进行pid,直接复制kill -9 命令去手动删除
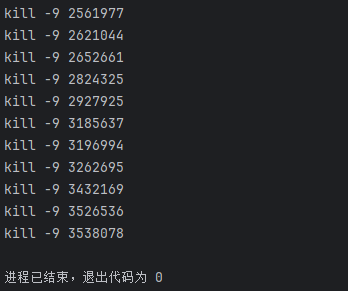
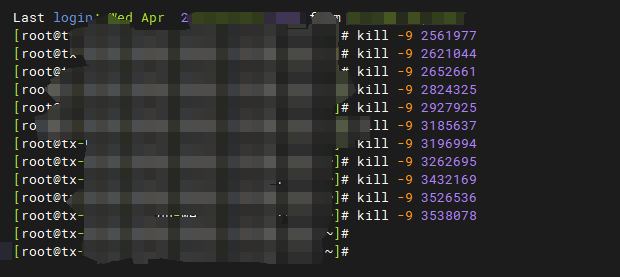
这样就能把卡住的爬虫全都扬咯
发表回复